
OTHER LINKS

Bridge Project

University of Rochester
WCNG: Emre Eskimez, Ana Tavares De Melo, Borja Rojo, Erik Nunez, Kwasi Nimako, Nick Weinstein and Wendi Heinzelman
ECE: Yichi Zhang and Zhiyao Duan
CSSP: Melissa Sturge-Apple, Patrick Davies and Loisa Bennetto
Former Members:
University of Rochester
WCNG: Na Yang, He Ba, Carmen Cortazar, Nancy Vargas, Yun Zhou, Jianbo Yuan, Thomas Horta, Weiyang Cai, Rajani Muraleedharan, and JoHannah Kohl
ECE: Mark Bocko and Zeljko Ignjatovic
CSSP: Fred Rogosch
Universitat Politecnica de Catalunya, Spain
Ilker Demirkol
University of Georgia
Jennifer Samp
University of Virginia
Steve Boker
Sponsor:

Project Website: Rochester Center for Research on Children and Families
Project overview: Emotion is the complex psychophysiological experience of an individual's state of mind as interacting with biochemical and environmental influences. Most existing emotion classification methodologies are based on subjective self-reported data. It has been found that prosodic variations in speech are closely related to people's emotion, thus automatic passive emotion classification becomes possible. In collaboration with researchers in the Clinical and Social Sciences in Psychology Department at the University of Rochester, the Bridge Project explores ways of detecting emotions from speech, without interpreting speech content, or using facial expressions or body gestures. This sort of emotion classification is likely to have a broader appeal, as it is less intrusive than interpreting speech content or capturing images. Health care providers and researchers can put emotion detectors and other behavior sensing technologies on mobile devices for patient monitoring or behavior studies. Also, emotion recognition technology will be an entry point for elaborate context-aware systems for future consumer electronic devices or services.
In our emotion classification system, speech signal processing methods are used to extract speech features, and the statistics of the speech features are used as metrics. Figure 1 shows the speech features that are considered, among which pitch, energy, and MFCCs are important features.
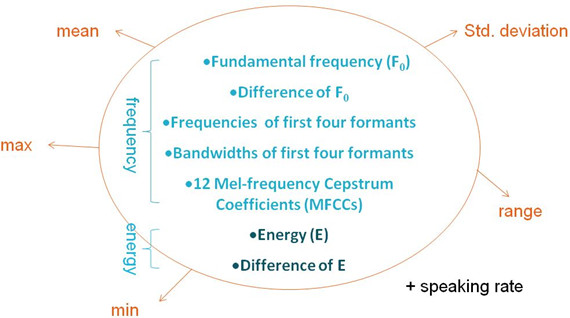
Figure 1: Statistics of extracted speech signal features
A short frame of speech from a male speaker is shown in Figure 2, where the speech waveform, spectrum, and formants are plotted.
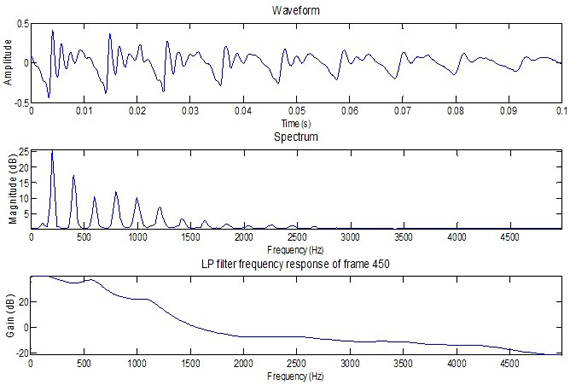
Figure 2: Signal waveform, spectrum, and formants of one frame for a male speaker
To find patterns in a speech signal that are related to emotion, we present an emotion classification system using several one-against-all support vector machines with a threshold-based fusion mechanism to combine the individual outputs, which provides the functionality to effectively increase the emotion classification accuracy at the expense of rejecting some samples as unclassified. Figure 3 shows the emotion classification system architecture, including training, one-against-all testing, and decision-level thresholding fusion. Details of our approach can be found in the publications listed in the below.
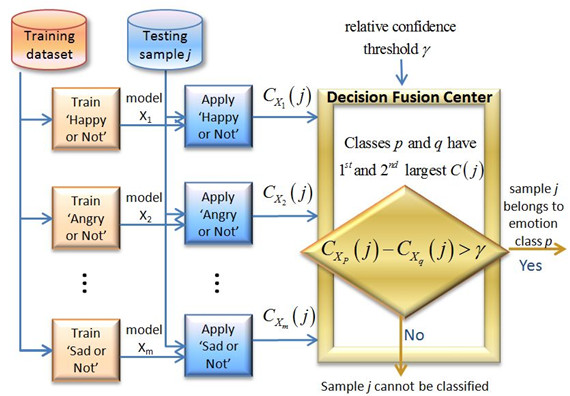
Figure 3: Emotion classification using one-against-all SVM and thresholding fusion
- A female speaker performing the "anger" emotion
- A female speaker performing the "disgust" emotion
- A female speaker performing the "happiness" emotion
- A female speaker performing the "neutral" emotion
- A female speaker performing the "fear" emotion
- A female speaker performing the "sadness" emotion
- A male speaker performing the "anger" emotion
- A male speaker performing the "disgust" emotion
- A male speaker performing the "happiness" emotion
- A male speaker performing the "neutral" emotion
- A male speaker performing the "fear" emotion
- A male speaker performing the "sadness" emotion
To test the robustness of the system, we also use the UGA dataset, which is a dataset with emotions acted by undergraduate students from the University of Georgia, thus the expressed emotions are less strong for the UGA dataset than the LDC dataset. Additionally, the data is much noisier in the UGA dataset than it is in the LDC dataset. The UGA dataset can be fully downloaded from here.
The MATLAB GUI for Speech-based Emotion Classification
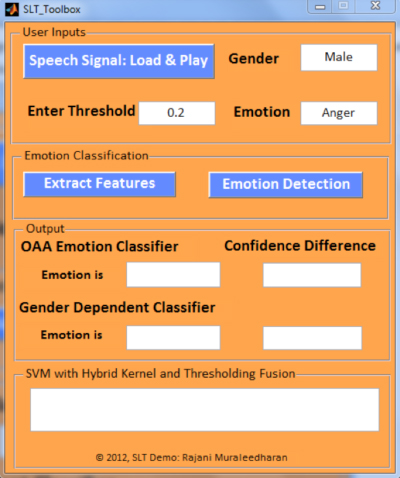
Figure 4: Emotion classification MATLAB GUI main panel
Step 1: File loading
The main panel of the GUI is shown in Figure 4. The user first chooses one speech file from the local directory. The gender of the speaker and the true emotion of the speech file will be automatically shown on the GUI. In this demo, the gender of the speaker is male, and his true emotion labeled in the LDC dataset is anger. Then the users enter their desired relative confidence threshold value, which is a value larger than or equal to 0. For example, we enter 0.2. A larger value means that we require a more stringent emotion classification result from the GUI.
Step 2: Emotion classification
The emotion classification consists of two steps: feature extraction and emotion classification using OAA SVM with thresholding fusion. As shown in Figure 5, the GUI plots selected speech features for each 60-ms long frame of the speech utterance, including pitch, energy, and the frequency of the first four formants.
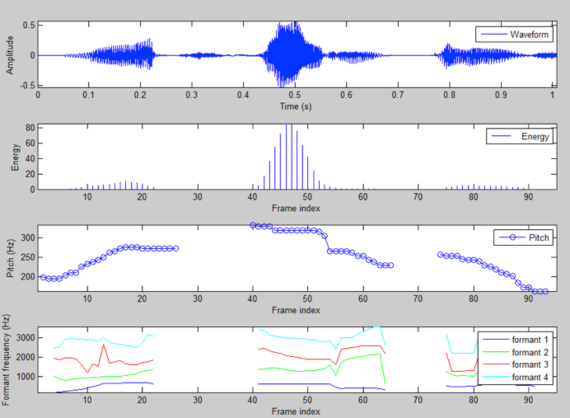
Figure 5: Emotion classification MATLAB GUI feature extraction
Step 3: Output emotion classification results
The GUI outputs the gender-independent emotion classification result onto a valence-arousal coordinate. As Figure 6 shows, the predicted angry emotion falls into the active and negative coordinate.
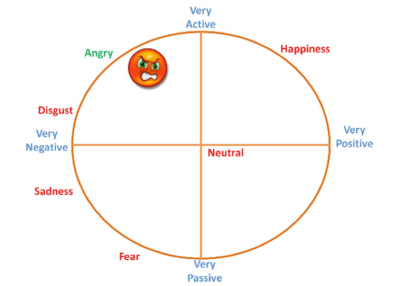
Figure 6: Emotion classification MATLAB GUI result outputs onto a valence-arousal coordinate
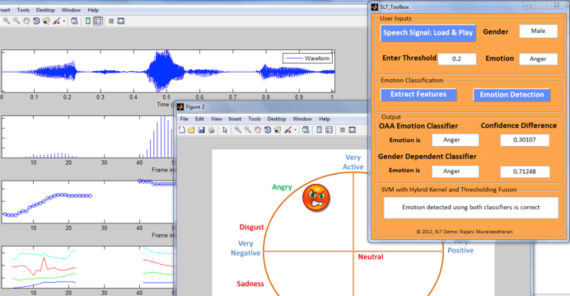
Figure 7: Emotion classification MATLAB GUI result outputs
Matlab code for the Speech-based Emotion Classification GUI can be downloaded from the Code section of the WCNG website.
MATLAB GUI Demonstration Video
The Noise-resilient BaNa Fundamental Frequency (F0) Detection
To test the noise resilience of BaNa, we create test speech data with different types of noise at different signal-to-noise ratio (SNR) values. For example, the following speech samples are generated by a female speaker performing the pride emotion, with 8 types of surrounding noise: babble noise, destroyer engine noise, destroyer operations noise, factory noise, high frequency channel noise, white noise, pink noise, and noise recorded in a Volvo vehicle. The SNR is 3dB.
- clean speech
- speech with 3dB babble noise
- speech with 3dB destroy engine noise
- speech with 3dB destroy operations noise
- speech with 3dB factory noise
- speech with 3dB high frequency channel noise
- speech with 3dB white noise
- speech with 3dB pink noise
- speech with 3dB vehicle noise
You can also listen to the following audio files with different SNR values of babble noise, which are performed by a male speaker with sadness emotion. The clean speech data is also provided.
- clean data
- speech with 20dB babble noise
- speech with 10dB babble noise
- speech with 3dB babble noise
- speech with 0dB babble noise
The source code for the BaNa F0 detection algorithm as well as the synthetic noisy speech files are available for download in the Code section of the WCNG website.
Additionally, the BaNa Android app can be downloaded via the Google PlayStore (search: BaNa Pitch Visualizer) or through this link.
Presentations
Publications
NOTE: A bug was found in the database used to generate the results in this paper! We are working to redo the experiments and report the true accuracy of our approach for emotion classification using Multiclass SVM with Hybrid Kernel and Thresholding Fusion.
Media Coverage
Additional interviews and news reports about the Bridge project include the Jay Thomas radio show on Sirius and XM Satellite radio in New York, and ABC News Radio.