DSCC383 Group I Team
Youssef Ouenniche, Ian Kaplan, Michael Kingsley, Goutham Swaminathan, Shiva Rahul Edara
Advisor: Professor Ajay Anand | Sponsor: Dr. Zidian Xie
Analysis & Modeling
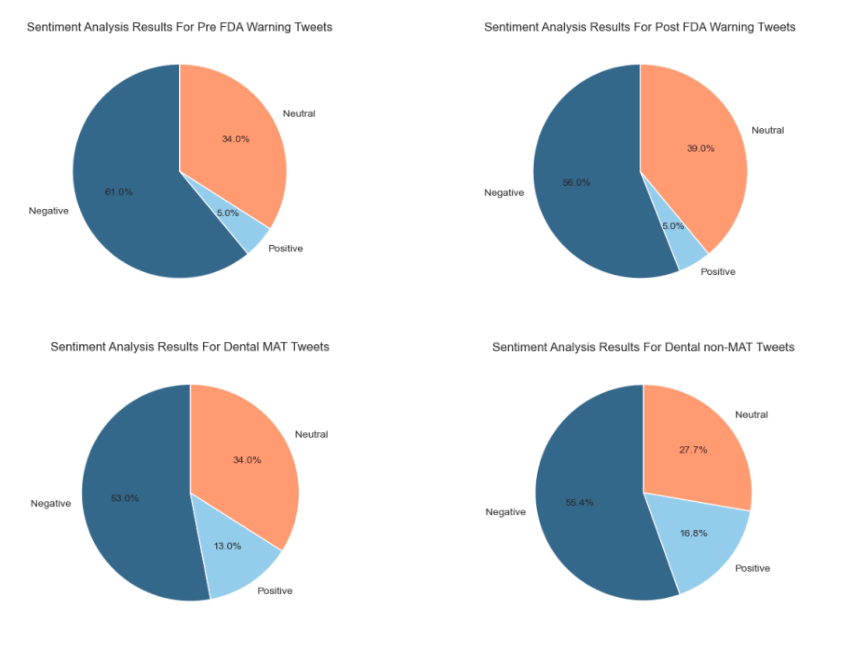
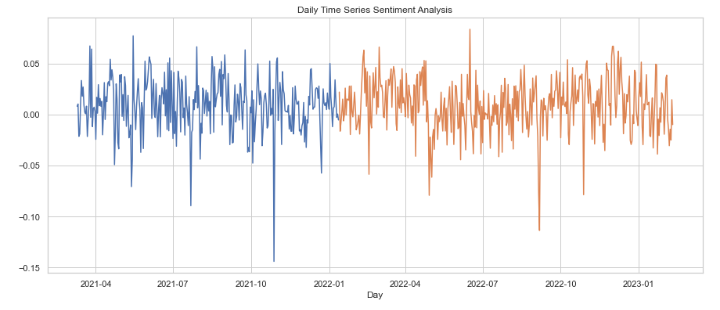
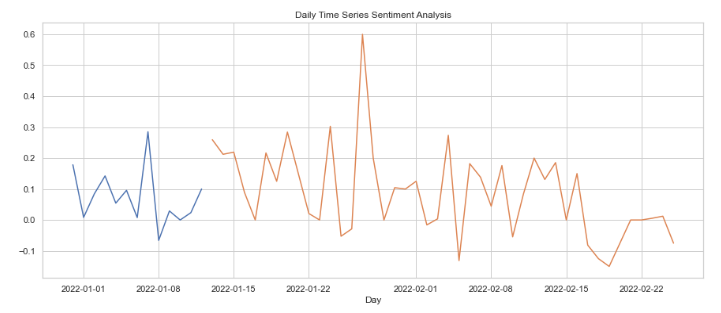
Background: Opioid Use Disorder (OUD) is a chronic brain disease characterized by persistent opioid use despite harmful consequences. There are a number of Medication-Assisted Treatments (MATs) for OUD, including buprenorphine and naloxone. However, these treatments are highly acidic tablets and film and have been shown to cause a variety of dental issues from cavities to tooth decay. The FDA issued a warning on the correlation on January 12, 2022.
Method: Optimization of BERT Model to identify opiate users from Twitter dataset, Twitter-roBERTa-base as well as TextBlob for Sentiment Analysis of both dental related Tweets of opiate users and opiate related Tweets before and after FDA warning and LDA Topic Modeling on Tweets.
Result: We achieved an 84% recall for ‘yes’ labeled tweets, predicted to represent opiate-consuming twitter users, and an 85% accuracy for our BERT model.
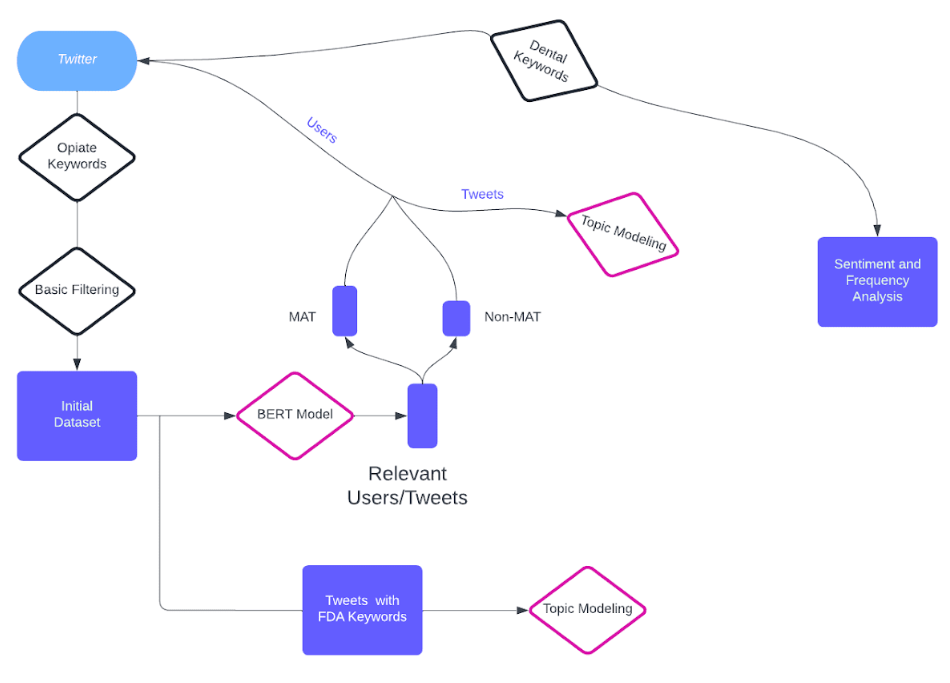
Data Cleaning: Twitter Data was collected by running the package ‘twint’ through Twitter’s API and recording all tweets containing one or more words from a keyword list about opiates, along with a few other keyword lists for Dr. Xie’s other projects. This initial tweet dataset was reduced down to those containing only the relevant keywords and from the United States.
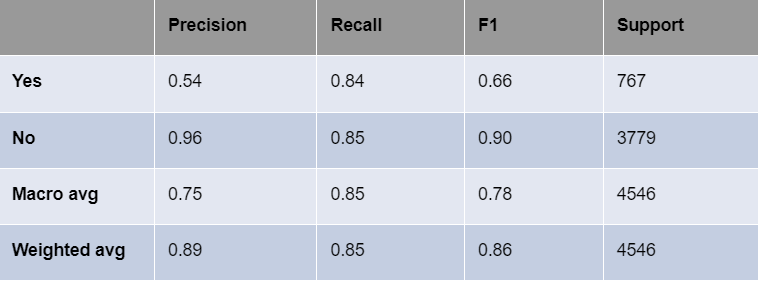
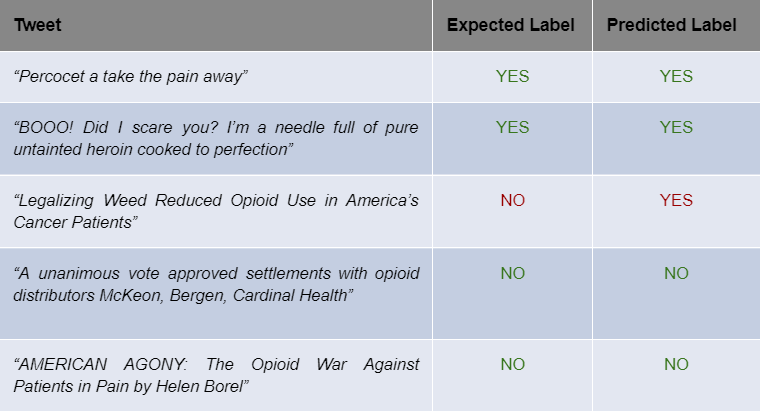
Model Development: In order to reduce our dataset down to tweets that referred to self-use, we trained a BERT model over a subset of our data. However, since our data was unlabelled, we had to hand label approximately 4500 tweets in order to train. Before splitting the work, we took a subset of 200 tweets and confirmed that we had a 91% similarity when hand labelling individually, giving us enough confidence to move forward.
Our final BERT model had an 84% recall score, which is our primary metric since it is merely an intermediary step in our project.
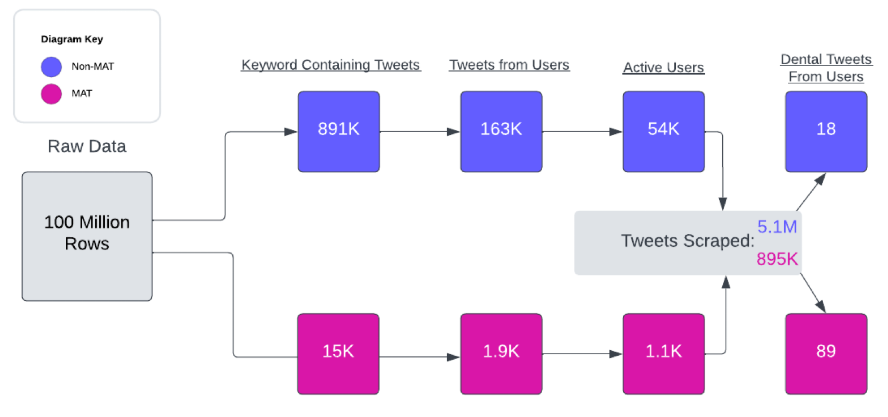
Data Collection: We started with our original dataset (provided by the sponsor). Using the initial dataset of over 100 million rows, we separated it into MAT and non-MAT data. After applying our model to identify opioid consumers, we then used the ‘stweet’ package to identify concurrent active Twitter users and the ‘SNScraper’ package for scraping. Finally, after scraping the entire history of tweets for all MAT users and a sample of 1.5k non MAT users, we filtered for relevant dental tweets. Our final dental tweets are only 19 for non-MAT out of over 5 million tweets, and 89 for MAT out of more than 895 thousand tweets.
Visualization Results
Summary & Conclusion
Based on the initial dataset provided by our sponsor, we conducted an extensive study on opiate users on Twitter. Our study began with filtering the dataset using specific opiate-related keywords, including “Fentanyl,” to form an initial dataset. We then employed a BERT-Classifier, which we meticulously hand-labeled and trained, to ensure that our study focused on opiate users rather than individuals who merely mentioned opiates on Twitter. Concurrently, we pursued a secondary objective by filtering tweets containing relevant FDA keywords, which we subsequently subjected to topic modeling. Using our labeled BERT dataset, we split users into MAT and non-MAT categories, undertaking topic modeling and Twitter page scraping to obtain additional data.
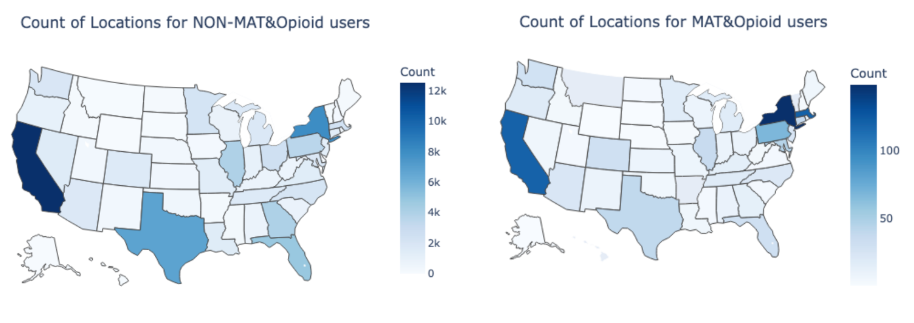
Our study culminated with filtration for dental keywords and the computation of sentiment scores, along with further topic modeling. We also conducted data processing and cleaning to ensure that our analysis was accurate and efficient. Overall, our study revealed insights into the behaviors and characteristics of opiate users on Twitter. We found that there were some differences in the language used by MAT and non-MAT users, with non-MAT users using more negative language and focusing more on issues related with Methadone clinics. We also found that sentiment scores varied depending on the opiate-related keywords used, with some keywords having more negative sentiment than others. In addition, our analysis of Twitter data provided insights into the geographical distribution of opioid and MAT users, with California having the highest number of opioid users on both the MAT and non MAT sides. This information can help inform targeted interventions and resources for regions experiencing higher rates of opioid use. However, our analysis also revealed a limited number of tweets mentioning dental issues related to opioid use, making it difficult to draw conclusions on this potential issue. Further research is necessary to better understand the impact of opioids on dental health, particularly among MAT users, and to develop appropriate interventions.
In a nutshell, social media data can be a valuable tool for understanding trends and patterns in opioid use, but it should be used in conjunction with other sources of data for a comprehensive understanding of the issue.
Future Work
While our study provides valuable insights into opiate users on Twitter, there are several avenues for future research that we recommend exploring. Firstly, our analysis revealed a limited number of tweets mentioning dental issues related to opioid use, highlighting the need for further research on the impact of opioids on dental health. A more in-depth investigation of this issue, particularly among MAT users, could lead to the development of targeted interventions and resources for individuals struggling with this problem. Additionally, future studies could explore the use of other social media platforms, such as Facebook or TikTok to identify more comprehensive patterns in opioid use and behavior.
Another interesting area for future research is to investigate the relationship between opioid use and mental health. Social media data could be leveraged to identify patterns in tweets related to depression, anxiety, and other mental health conditions that could be associated with opioid use. Understanding the link between opioid use and mental health could help develop appropriate interventions to the issue.
Finally, future research could evaluate the impact of different interventions and policies, such as MAT programs or prescription drug monitoring programs, to identify best practices and inform future policy decisions.
Acknowledgements
We want to specially thank Professor Ajay Anand for his guidance and help throughout our project. Professor Anand’s recommendations were incredibly valuable in our progress within the different steps of this project. Similarly, we would like to thank Dr. Zidian Xie for sponsoring this project, and giving us this opportunity to work with him. This research allowed us to explore different facets of work with Social Media data and the challenges encountered created a great learning opportunity for the team.
References
- Ankthon. “Python sentiment Analysis Using VADER.” GeeksForGeeks, 7 Oct. 2021.
- Barbieri, Francesco, et al. TWEETEVAL: Unified Benchmark and Comparative Evaluation for Tweet Classification. 26 Oct. 2020
- Desai, Rashi. “How to scrape millions of tweets using SNScrape.” Medium, 21 June 2021.
- Ghanoum, Tarek. “Topic Modelling in Python with SpaCy and Gensim.” Medium, 1 Jan. 2022.
- Loria, Steven. “TextBlob.” TextBlob, 0.16.0, 1 Oct. 2021.
- Sanguineti, Marco. “Implementing Custom Loss Functions in PyTorch.” Medium, 23 Feb. 2023.
- Shristikotaiah. “FLAIR – A Framework for NLP” GeeksForGeeks, 26 Nov. 2020.
- Watroba, Marcin. “STweet.” PyPI, 0.1.0, 28 Nov. 2020.
- Winastwan, Ruben. “Text Classification with BERT in PyTorch.” Medium, 10 Nov. 2021.
- Xie, Zidian, CTSI UR Data Science Capstone/Practicum Projects. Jan. 2023. PowerPoint Presentation.